


There are IT outages. There are significant IT outages. There are massive IT outages.
And then, there is the “think of your worst nightmare as an IT pro and then make it 100x worse and you’re not even close” CrowdStrike IT outage that erupted across the world on July 19.
This is an extremely fast-moving situation, and it’s going to take a while to unpack the details and get things back to normal. However, let’s recap what we know so far, and point to some early lessons learned.
What is CrowdStrike?
CrowdStrike is a US-based cybersecurity firm that provides software to many large organizations around the world, including several Fortune 500 enterprises. Its flagship product is called Falcon, which is an endpoint detection and response (EDR) platform that scans machines for signs of unusual or nefarious activity, and lock down any threats. In order for Falcon to do its job, it must be closely integrated with the core software of the systems that it runs on — including Microsoft Windows.
What Happened?
We now know that the outage was triggered by a defective Falcon update, which caused machines running Windows to crash. Now, considering that more than 6,000 companies around the world use Falcon, this alone would have been disastrous. But the story gets much, much worse.
The crash sent affected machines into a recovery boot loop. As a result, instead of chugging along through (tedious but not terrifying) boot-up sequences and coming back online, users were greeted by an old Microsoft nemesis that is even more universally-hated than Clippy: the infamous Blue Screen of Death (BSOD).
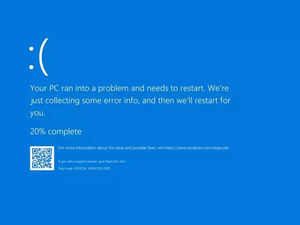
The catastrophic event affected thousands of companies worldwide, and resulted in grounded flights and stalled banking and hospitals services. In fact, some hospitals forced to temporarily ditch their multi-million dollar network and computing infrastructure and revert to old fashioned paper. Overall, an estimated 8.5 million devices were affected.
The Silver Lining
Even the most dedicated optimists will be hard-pressed to find anything positive about what many are calling the biggest IT outage of all time (some observers have mused that we’re facing Y2K, yet 24 years late). However, we do have two small entries for the “It Could Have Been Worse” file.
The first is that CrowdStrike was quick to confirm in a statement that the outage was caused by a faulty update and not a cyberattack. True, this is hardly a reason to celebrate. But we can all agree that pinning this disaster on flawed practices and (possibly) incompetent staff at CrowdStrike is far preferred to crediting bad actors.
The second is that Falcon is built for large organizations, and as such Windows 10 home users — who typically rely on endpoint antivirus software such as Norton, McAfee and Windows Defender — were not affected (which also meant that millions of workers who were told to stay home on July 19, or were sent home early because they couldn’t get anything done, had plenty of time to jump on their PC and turn the social media landscape into a real-time CrowdStrike Disaster Watch Party).
What is Being Done?
As mentioned, this is a fast-moving situation and developments are changing by the day (and sometimes by the hour). However, at the time of this writing, CrowdStrike has stated that Windows hosts that have not been impacted do not require any action, as the problematic channel file has been reverted. In addition, Windows hosts that were brought online after 5:27am UTC on July 20 will not be impacted.
CrowdStrike has also published workarounds for individual hosts, and public cloud environments (including virtual). These can be found on the company’s website, along with documentation for BitLocker recovery across different tools (such as Tanium, Citrix, etc.).
And on an upbeat note: as of July 21 reports are trickling in that some airports, hospitals, and other affected organizations are on the path to restoring normal operations.
What Have We Learned So Far?
It will take weeks, or probably months, to do a complete post-mortem. However, this shouldn’t stop us from trying to learn as much as we can right now:
1. We are reminded that in the IT world, outages happen.
Some folks outside the IT world believe that IT software and systems are flawless, and should always work perfectly. And when it doesn’t, they panic – like the stranded airport passengers who unleashed their rage on airline staff who had absolutely nothing to do with the IT outage, and probably have never even heard of CrowdStrike.
The truth is that outages can and will happen (as we unfortunately experienced with the Devolutions Force a few months ago). As such, robust, updated, and documented disaster recovery plans are essential. These plans should include detailed, clear protocols and processes for rapidly identifying, isolating, and resolving different scenarios and issues. What’s more, once these plans need to be tested regularly through simulated drills, in order to proactively spot vulnerabilities that can be proactively improved.
2. A comprehensive update management approach is critical.
This approach must govern pre-deployment testing across multiple staging environments and configurations, in order to proactively detect potential issues. The process should include automated testing, manual testing, and regression testing, which helps ensure that new updates do not interfere with existing functionalities.
And just as importantly: this effort should be led by CIOs and CTOs, and not dumped on SysAdmins who often end up being “a lone voice in the wilderness” and accused of being bureaucratic and inefficient, when all they are trying to do is keep their company from making the headlines for all of the wrong reasons.
3. Monitor for anomalies post-deployment.
Keep a close eye after deployment by leveraging enhanced monitoring and incident response capabilities, which must be supported by easy reporting functionality. As cloud computing and data center company LightEdge advises: “Utilizing advanced monitoring tools to detect anomalies immediately post-deployment enables rapid intervention. Real-time monitoring and alerting systems should be in place to catch issues as they occur. Developing detailed incident response plans with clear protocols for quick identification, isolation, and resolution of issues is vital. These plans should include root cause analysis and post-incident reviews to continuously improve response strategies.”
4. Plan for enhanced resilience.
Companies need to implement redundancy and failover mechanisms to ensure that critical systems remain online even if one component fails. Javed Abed, an assistant professor of information systems at Baltimore’s Johns Hopkins Carey Business School, told CNBC: “A single point of failure shouldn’t be able to stop a business, and that is what happened. You can’t rely on only one cybersecurity tool. While building redundancy into enterprise systems is costly, what happened Friday is more expensive. I hope this is a wake-up call, and I hope it causes some changes in the mindsets of the business owners and organizations to revise their cybersecurity strategies.”
Were You Affected & What’s Your Advice?
We’ll keep a close eye on the Colossal CrowdStrike Crash of ‘24, and publish updates as we learn more.
In the meantime, please share if your company was affected by the outage, and to what extent. Please also provide your opinions and advice. What other lessons learned, wisdom, and best practices would you highlight?


