


Il y a des pannes informatiques. Il y a des pannes informatiques importantes. Il y a des pannes informatiques massives.
Et puis, il y a la panne informatique de CrowdStrike, qui a fait trembler le monde entier le 19 juillet, vous faisant penser à votre pire cauchemar en tant que professionnel de l'informatique, multiplié par 100.
C'est une situation en évolution très rapide, et il faudra un certain temps pour démêler les détails et revenir à la normale. Cependant, récapitulons ce que nous savons jusqu'à présent et soulignons quelques premières leçons apprises.
Qu'est-ce que CrowdStrike?
CrowdStrike est une entreprise de cybersécurité basée aux États-Unis qui fournit des logiciels à de nombreuses grandes organisations à travers le monde, y compris plusieurs entreprises du Fortune 500. Son produit phare s'appelle Falcon, une plateforme de détection et de réponse sur les terminaux (EDR) qui scanne les machines à la recherche de signes d'activité inhabituelle ou néfaste et verrouille les menaces. Pour que Falcon fasse son travail, il doit être étroitement intégré au logiciel de base des systèmes sur lesquels il fonctionne, y compris Microsoft Windows.
Que s'est-il passé?
Nous savons maintenant que la panne a été déclenchée par une mise à jour défectueuse de Falcon, qui a provoqué des pannes sur les machines exécutant Windows. Compte tenu du fait que plus de 6 000 entreprises dans le monde utilisent Falcon, cela aurait déjà été désastreux en soi. Mais l'histoire est bien pire.
Le crash a envoyé les machines affectées dans une boucle de récupération au démarrage. En conséquence, au lieu de traverser (des séquences de démarrage fastidieuses mais pas terrifiantes) et de revenir en ligne, les utilisateurs ont été accueillis par un vieil ennemi de Microsoft encore plus universellement détesté que Clippy : le fameux Écran Bleu de la Mort (BSOD).
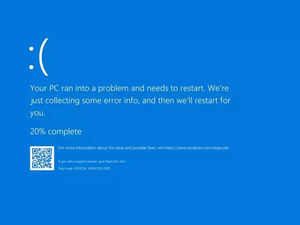
L'événement catastrophique a affecté des milliers d'entreprises dans le monde entier, entraînant des vols annulés, des services bancaires et hospitaliers bloqués. En fait, certains hôpitaux ont été contraints de mettre temporairement de côté leur infrastructure réseau et informatique de plusieurs millions de dollars et de revenir au bon vieux papier. Au total, on estime que 8,5 millions de dispositifs ont été affectés.
La lueur d'espoir
Même les optimistes les plus dévoués auront du mal à trouver quelque chose de positif dans ce que beaucoup appellent la plus grande panne informatique de tous les temps (certains observateurs ont même suggéré que nous faisons face à Y2K, mais avec 24 ans de retard). Cependant, nous avons deux petites entrées pour le dossier « Cela aurait pu être pire ».
La première est que CrowdStrike a rapidement confirmé dans un communiqué que la panne était causée par une mise à jour défectueuse et non par une cyberattaque. Certes, ce n'est guère une raison de célébrer. Mais nous pouvons tous convenir qu'attribuer cette catastrophe à des pratiques défaillantes et (peut-être) à un personnel incompétent chez CrowdStrike est bien préférable que de la mettre sur le dos d'acteurs malveillants.
La seconde est que Falcon est conçu pour les grandes organisations, et en tant que tel, les utilisateurs domestiques de Windows 10 — qui s'appuient généralement sur des logiciels antivirus tels que Norton, McAfee et Windows Defender — n'ont pas été affectés (ce qui a également signifié que des millions de travailleurs qui ont été invités à rester chez eux le 19 juillet, ou ont été renvoyés chez eux plus tôt parce qu'ils ne pouvaient rien faire, ont eu beaucoup de temps pour sauter sur leur PC et transformer le paysage des médias sociaux en une véritable soirée de surveillance des catastrophes CrowdStrike en temps réel).
Que fait-on?
Comme mentionné, il s'agit d'une situation en évolution rapide et les développements changent chaque jour (et parfois chaque heure). Cependant, au moment de la rédaction de cet article, CrowdStrike a déclaré que les hôtes Windows qui n'ont pas été impactés ne nécessitent aucune action, car le fichier de canal problématique a été annulé. De plus, les hôtes Windows qui ont été mis en ligne après 5h27 UTC le 20 juillet ne seront pas impactés.
CrowdStrike a également publié des solutions de contournement pour les hôtes individuels et les environnements de cloud public (y compris virtuels). Celles-ci peuvent être trouvées sur le site Web de la société, ainsi que la documentation pour la récupération de BitLocker à travers différents outils (tels que Tanium, Citrix, etc.).
Et sur une note positive : à partir du 21 juillet, des rapports indiquent que certains aéroports, hôpitaux et autres organisations affectées sont sur la voie de la restauration des opérations normales.
Qu'avons-nous appris jusqu'à présent?
Il faudra des semaines, voire probablement des mois, pour faire un post-mortem complet. Cependant, cela ne devrait pas nous empêcher d'essayer d'apprendre autant que nous le pouvons dès maintenant :
1. Nous sommes rappelés que dans le monde de l'informatique, les pannes arrivent.
Certaines personnes en dehors du monde de l'informatique croient que les logiciels et les systèmes informatiques sont parfaits et devraient toujours fonctionner parfaitement. Et quand ce n'est pas le cas, ils paniquent – comme les passagers bloqués à l'aéroport qui ont déversé leur rage sur le personnel des compagnies aériennes qui n'avait absolument rien à voir avec la panne informatique et probablement n'avaient même jamais entendu parler de CrowdStrike.
La vérité est que des pannes peuvent et vont se produire (comme nous l'avons malheureusement expérimenté avec Devolutions Force il y a quelques mois). En conséquence, des plans de reprise après sinistre robustes, mis à jour et documentés sont essentiels. Ces plans doivent inclure des protocoles et des processus détaillés et clairs pour identifier rapidement, isoler et résoudre différents scénarios et problèmes. De plus, ces plans doivent être testés régulièrement à travers des exercices simulés, afin de détecter les vulnérabilités qui peuvent être améliorées de manière proactive.
2. Une approche globale de la gestion des mises à jour est critique.
Cette approche doit régir les tests de pré-déploiement à travers plusieurs environnements et configurations de mise en scène, afin de détecter proactivement les problèmes potentiels. Le processus doit inclure des tests automatisés, des tests manuels et des tests de régression, qui aident à garantir que les nouvelles mises à jour n'interfèrent pas avec les fonctionnalités existantes.
Et tout aussi important : cet effort doit être dirigé par des CIO et des CTO, et non pas imposé aux administrateurs systèmes qui finissent souvent par être « une voix solitaire dans le désert » et accusés d'être bureaucratiques et inefficaces, alors qu'ils essaient simplement d'empêcher leur entreprise de faire la une des journaux pour toutes les mauvaises raisons.
3. Surveiller les anomalies après le déploiement.
Surveiller de près après le déploiement en utilisant des capacités améliorées de surveillance et de réponse aux incidents, qui doivent être soutenues par des fonctionnalités de rapport facile. Comme le conseille la société de cloud computing et de centre de données LightEdge : « Utiliser des outils de surveillance avancés pour détecter immédiatement les anomalies après le déploiement permet une intervention rapide. Des systèmes de surveillance et d'alerte en temps réel doivent être en place pour détecter les problèmes dès qu'ils se produisent. Développer des plans de réponse aux incidents détaillés avec des protocoles clairs pour une identification rapide, l'isolement et la résolution des problèmes est vital. Ces plans doivent inclure une analyse des causes profondes et des examens post-incidents pour améliorer continuellement les stratégies de réponse. »
4. Planifier une résilience accrue.
Les entreprises doivent mettre en œuvre des mécanismes de redondance et de basculement pour garantir que les systèmes critiques restent en ligne même si un composant tombe en panne. Javed Abed, professeur adjoint de systèmes d'information à la Carey Business School de Baltimore, a déclaré à CNBC : « Un point de défaillance unique ne devrait pas pouvoir arrêter une entreprise et c'est ce qui s'est passé. Vous ne pouvez pas compter sur un seul outil de cybersécurité. Bien que la redondance dans les systèmes d'entreprise soit coûteuse, ce qui s'est passé vendredi est plus cher. J'espère que c'est un signal d'alarme et j'espère que cela entraînera des changements dans les mentalités des propriétaires d'entreprises et des organisations pour revoir leurs stratégies de cybersécurité. »
Avez-vous été affecté et quels sont vos conseils?
Nous garderons un œil attentif sur le colossal crash de CrowdStrike de 2024 et publierons des mises à jour au fur et à mesure que nous en apprendrons davantage.
En attendant, veuillez partager si votre entreprise a été affectée par la panne et dans quelle mesure. Veuillez également fournir vos opinions et conseils. Quelles autres leçons apprises, sagesses et meilleures pratiques mettriez-vous en avant?


