

Es gibt IT-Ausfälle. Es gibt bedeutende IT-Ausfälle. Es gibt massive IT-Ausfälle.
Und dann gibt es noch den CrowdStrike-IT-Ausfall, der am 19. Juli weltweit auftrat: Stellen Sie sich Ihren schlimmsten Albtraum als IT-Experte vor, machen Sie ihn 100-mal schlimmer und Sie sind nicht einmal nah dran.
Diese Situation entwickelt sich extrem schnell und es wird eine Weile dauern, bis die Einzelheiten geklärt sind und alles wieder normal läuft. Lassen Sie uns dennoch zusammenfassen, was wir bisher wissen, und einige erste Lehren daraus ziehen.
Was ist CrowdStrike?
CrowdStrike ist ein US-amerikanisches Unternehmen für Cybersicherheit, das Software für viele große Unternehmen auf der ganzen Welt anbietet, darunter mehrere Fortune-500-Unternehmen. Sein Vorzeigeprodukt heißt Falcon. Dabei handelt es sich um eine Endpoint Detection and Reponse (EDR)-Plattform, die Rechner auf Anzeichen ungewöhnlicher und bösartiger Aktivitäten untersucht und Bedrohungen abwehrt. Damit Falcon seine Aufgabe erfüllen kann, muss es eng in die Kernsoftware der Systeme, auf denen es läuft, integriert werden - so auch in Microsoft Windows.
Was ist passiert?
Wir wissen jetzt, dass der Ausfall durch ein fehlerhaftes Falcon-Update ausgelöst wurde, das zum Absturz von Rechnern mit Windows geführt hat. In Anbetracht der Tatsache, dass mehr als 6000 Unternehmen weltweit Falcon verwenden, wäre dies allein schon eine Katastrophe gewesen. Aber die Geschichte wird noch viel, viel schlimmer.
Der Absturz versetzte die betroffenen Rechner in eine Wiederherstellungs-Bootschleife. Anstatt sich durch (mühsame, aber nicht furchterregende) Boot-Sequenzen zu quälen und wieder online zu gehen, wurden die Nutzer von einem alten Erzfeind von Microsoft begrüßt, der weltweit noch verhasster ist als Clippy: dem berüchtigten Blue Screen of Death (BSOD).
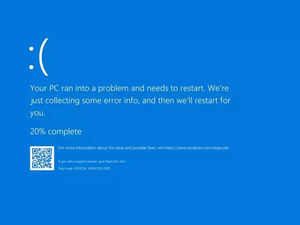
Das katastrophale Ereignis betraf Tausende von Unternehmen auf der ganzen Welt und führte zu Flugverboten und zum Stillstand von Bank- und Krankenhausdiensten. Einige Krankenhäuser sahen sich sogar gezwungen, Ihre mehrere Millionen Dollar teure Netzwerk- und Computerinfrastruktur vorübergehend abzuschalten und auf das veraltete Papier zurückzugreifen. Insgesamt waren schätzungsweise 8.5 Millionen Geräte betroffen.
Der Silberstreif am Horizont
Selbst die passioniertesten Optimisten werden sich schwer tun, dem, was viele als den größten IT-Ausfall aller Zeiten bezeichnen, etwas Positives abzugewinnen. (Einige Beobachter haben sogar spekuliert, dass wir den Millennium Bug Y2K erleben, nur mit 24 Jahren Verspätung). Wir haben jedoch auch zwei Einträge für die Datei „Es hätte schlimmer kommen können“.
Zum einen hat CrowdStrike schnell in einer Erklärung bestätigt, dass der Ausfall durch ein fehlerhaftes Update und nicht durch einen Cyberangriff verursacht wurde. Zugegeben, das ist kaum ein Grund zum Feiern. Aber wir können uns sicher alle darauf einigen, dass es weitaus besser ist, dieses Unglück auf fehlerhafte Praktiken und (möglicherweise) inkompetente Mitarbeiter bei CrowdStrike zurückzuführen, als böse Akteure dafür verantwortlich zu machen.
Der zweite Grund ist, dass Falcon für große Unternehmen entwickelt wurde und daher Windows 10-Heimanwender, die sich in der Regel auf Antivirensoftware für Endgeräte wie Norton, McAfee und Windows Defender verlassen, nicht betroffen waren. (Dies beutet auch, dass Millionen von Arbeitnehmern, die am 19.Juli zu Hause bleiben mussten oder früher nach Hause geschickt wurden, weil sie nicht arbeiten konnten, reichlich Zeit hatten, sich an ihren PC zu setzen und in den sozialen Medien eine CrowdStrike-Katastrophen-Beobachtungs-Party in Echtzeit zu veranstalten).
Was wird unternommen?
Wie bereits erwähnt, handelt es sich um eine sich schnell entwickelnde Situation und es gibt täglich (und manchmal sogar stündlich) neue Erkenntnisse. Zum Zeitpunkt der Erstellung dieses Artikels hat CrowdStrike jedoch erklärt, dass Windows-Hosts, die nicht betroffen sind, keinerlei Maßnahmen ergreifen müssen, da die problematische Channel-Datei zurückgenommen worden sei. Darüber hinaus sind Windows-Hosts, die am 20. Juli nach 5:27 Uhr UTC online gestellt wurden, nicht betroffen.
Weiterhin hat CrowdStrike Umgehungslösungen für einzelne Hosts und öffentliche Cloud-Umgebungen (einschließlich virtueller) veröffentlicht. Diese sind auf der Website des Unternehmens zu finden, zusammen mit einer Dokumentation für die BitLocker-Wiederherstellung über verschiedene Tools (wie Tanium, Citrix, etc.).
Und noch eine positive Meldung: Seit dem 21. Juli treffen Berichte darüber ein, dass einige Flughäfen, Krankenhäuser und andere betroffene Unternehmen auf dem Weg zur Wiederherstellung des Normalbetriebs sind.
Was haben wir bis jetzt gelernt?
Es wird Wochen, wahrscheinlich sogar Monate dauern, bis eine vollständige Bestandsaufnahme abgeschlossen ist. Das sollte uns aber nicht davon abhalten, jetzt schon so viel wie möglich zu lernen:
1. Wir werden daran erinnert, dass es in der IT-Welt zu Ausfällen kommen kann.
Einige Leute außerhalb der IT-Welt glauben, dass IT-Software und -Systeme fehlerfrei sind und immer perfekt funktionieren sollten. Und wenn das nicht der Fall ist, geraten sie in Panik - wie die auf Flughäfen gestrandeten Passagiere, die ihre Wut an den Mitarbeitern der Fluggesellschaften ausließen, die absolut nichts mit dem IT-Ausfall zu tun hatten und wahrscheinlich noch nie etwas von CrowdStrike gehört haben.
Die Wahrheit ist, dass es zu Ausfällen kommen kann und wird (wie wir leider vor einigen Monaten mit Devolutions Force erlebt haben). Daher sind stabile, aktualisierte und dokumentierte Pläne für die Notfallwiederherstellung unerlässlich. Diese Pläne sollten detaillierte, klare Protokolle und Prozesse für die schnelle Identifizierung, Isolierung und Lösung verschiedener Szenarien und Probleme enthalten. Darüber hinaus müssen diese Pläne regelmäßig durch simulierte Übungen getestet werden, um proaktiv Schwachstellen zu erkennen, die proaktiv verbessert werden können.
2. Ein umfassender Ansatz zur Updateverwaltung ist entscheidend.
Dieser Ansatz muss Tests vor der Bereitstellung in mehreren Staging-Umgebungen und Konfigurationen vorsehen, um potenzielle Probleme proaktiv zu erkennen. Der Prozess sollte automatisierte und manuelle Tests sowie Regressionstests umfassen, um sicherzustellen, dass neue Aktualisierungen die bestehenden Funktionen nicht beeinträchtigen.
Und was ebenso wichtig ist: Diese Bemühungen sollten von CIOs und CTOs geleitet und nicht auf Systemadministratoren abgewälzt werden, die oft als „einsame Stimme in der Wildnis“ enden und beschuldigt werden, bürokratisch und ineffizient zu sein, während sie nur versuchen, zu verhindern, dass ihr Unternehmen aus den falschen Gründen in die Schlagzeilen gerät.
3. Achten Sie nach der Bereitstellung auf Anomalien.
Behalten Sie auch nach der Bereitstellung alles genau im Auge, indem Sie erweiterte Funktionen zur Überwachung und zur Reaktion auf Vorfälle nutzen, die durch einfache Berichtsfunktionen unterstützt werden müssen. Das Cloud-Computing- und Rechenzentrumsunternehmen LightEdge empfiehlt: „Der Einsatz fortschrittlicher Überwachungstools zur Erkennung von Anomalien unmittelbar nach der Bereitstellung ermöglicht ein schnelles Eingreifen. Es sollten Echtzeit-Überwachungs- und Warnsysteme vorhanden sein, um Probleme zu erkennen, sobald sie auftauchen. Die Entwicklung detaillierter Reaktionspläne für Zwischenfälle mit klaren Protokollen für die schnelle Identifizierung, Isolation und Lösung von Problemen ist von entscheidender Bedeutung. Dies Pläne sollten eine Ursachenanalyse und Überprüfung nach einem Vorfall beinhalten, um die Reaktionsstrategien kontinuierlich zu verbessern.“
4. Planen Sie eine verbesserte Widerstandsfähigkeit.
Unternehmen müssen Redundanz- und Ausfallsicherungs-Mechanismen implementieren, um sicherzustellen, dass kritische Systeme online bleiben, auch wenn eine Komponente ausfällt. Javed Abed, Assistenzprofessor für Informatiksysteme an der Johns Hopkins Carey Business School in Baltimore, erklärte gegenüber CNBC: „Ein einziger Fehler sollte ein Unternehmen nicht zum Stillstand bringen können, und genau das ist passiert. Man kann sich nicht nur auf ein einziges Tool für die Cybersicherheit verlassen. Der Einbau von Redundanz in Unternehmenssysteme ist zwar kostspielig, aber was am Freitag passiert ist, ist noch teurer. Ich hoffe, dass dies ein Weckruf ist und ich hoffe, es bewirkt einige Veränderungen in der Denkweise der Geschäftsinhaber und Unternehmen, damit sie ihre Cybersicherheitsstrategien überarbeiten.“
Waren Sie betroffen & was ist Ihr Rat?
Wir werden den kolossalen CrowdStrike-Absturz von 2024 weiter im Auge behalten und Updates veröffentlichen, sobald wir mehr erfahren.
Bitte teilen Sie uns in der Zwischenzeit mit, ob und in welchem Umfang Ihr Unternehmen von dem Ausfall betroffen war. Bitte teilen Sie auch Ihre Meinung und Ratschläge mit. Welche weiteren Lehren, Erkenntnisse und bewährten Verfahren würden Sie hervorheben?


